
Moving Ahead with Generative AI—Choosing your models
In a prior post we looked at how to get started with Generative AI, reviewing some key use cases for using Generative AI, the basis of prompting, and tool selection. If you haven’t had a chance to experiment on your own yet with generative AI, I’d suggest returning to that post and then diving in and using the tools yourself.
Once you have had the opportunity to explore the basic elements of generative AI models, it’s time to dig in a bit deeper to look at some of the various features that have emerged in the tools so that you can better match your job to be done with the right approach. Learning these additional tools will help you become more productive and get even more value from these tools. They may also help address limitations which you have observed in just using the standard or default features with your early explorations. So let’s roll up our sleeves and get going.
To help keep us grounded and practical we’ll be focusing on OpenAI and ChatGPT features in this post. Nevertheless, many of these features exist in the different vendor tools and we’ll point some of them out along the way where it isn’t too confusing (luckily many use the same names). In general, Google Gemini and Anthropic Claude feature similar feature sets, though there are some variations in how they are handled or may be more limited in scope.
Models Models Everywhere
One of the most challenging aspects of Generative AI today is the proliferation of different models and a tendency of the vendors to use confusing and inconsistent names. While this can be frustrating for us as users, it’s really a problem of abundance. The technology is advancing so quickly that new capabilities are being unlocked every few weeks, though they often come about with tradeoffs in quality, speed, and cost that have led the vendors to release all of these different versions. At the time of writing this, ChatGPT has 7 different models which you can choose from!
The basic dimensions of models (which are usually–but not always–indicated in their names) cover the following aspects.
Model Generation. The original ChatGPT was listed as version 3.5 (it was based on the original GPT versions, which were technical tools without chat), and since then major versions have included 4, 4.5, and 4.1 (which is recently available in the Chat tools, and, confusingly, was released after 4.5). Each new major version is typically trained on more data, using more computing power, and with the latest techniques and advances. They are also trained on more recent data, and so have more current knowledge (often referred to as the cut-off date for a model). Model generation is the broadest measure of capability, and usually the higher the version the better the tool, though they can also be more expensive to start. These numbered versions are typical across all of the vendors, though they don’t really have any relation to each other (the latest Google model is Gemini 2.5 and the most advanced model from Anthropic is Claude 3.7)
Model Speed. The challenge with the most advanced models is that they use a lot of computing power to run which also means that they can be slow to generate output. As a result, most model providers create “light” versions of their models which run faster, are cheaper to use, though tend not to be as advanced in their capabilities or how they perform on complex tasks. But for many types of work, they are more than good enough. In the standard chat tools the speed difference isn’t all that noticeable (unless you are a speed reader), so these light models are often used for the free versions of the tools or for developers building their own applications who are trying to control speed or costs. These light versions in ChatGPT are currently called “mini” in their name. On the opposite end, there are a few models labeled “high” which will be larger, and therefore slower and more expensive. Google calls their lightweight models “flash” versions and Anthropic has released some models labeled “instant.”
Modality Support. Modality is the way that different types of input are described. Originally the tools just supported text (chat) input so you had to interact with them only with text. Though less popular, there are also models that can handle audio (speech), images, and video as input. Output can also be multi-modal as well–the typical written text output, but there are models that generate speech, images, and video as output. While these used to be separate sets of features, they have increasingly become features of single models, which are referred to as “multi modal.” What modalities are supported isn’t always clear in the name, though the “o” in ChatGPT 4o stands for “omni” in reference to its support for text, audio, image, and limited video inputs. If you want to use something other than text, you may need to do some light research to find which models support other modalities. There are also subtleties in what it means to “support” a certain mode, particularly with respect to audio and video where there may be limits on size, duration, or exactly how it behaves that you may need to explore in more details based on your use case.
Model Class. A recent research breakthrough was the realization that if you let a model “think” longer when solving a problem you could get better results, especially for complex problems or complicated, multi-step tasks. The result was the release of a new class of “reasoning” models. While these models are considerably more powerful, they are much slower and significantly more expensive to run because the computer is given more time to work on a particular problem. Note that even though some of these models are described as “mini” this is in the context of a reasoning model, and so are still much slower than standard models. Open AI has released these as their “o” class models (though different from the “o” in 4o). The original model was o1, followed by o3 and now o4 (o2 was skipped for copyright reasons). Google refers to some of their models as “Thinking” while Anthropic takes a slightly different approach and lets users choose how much “thinking time” the model can use instead of offering different versions.
While many of these features are key distinctions now, over time these distinctions are likely to become less obvious. The models themselves will evolve to support the features together, and decide behind the scenes what specific features or capabilities should be used, with only the most advanced or specialized users needing to make their own choices.
The table below describes some of these key features across the different ChatGPT models that are currently available.
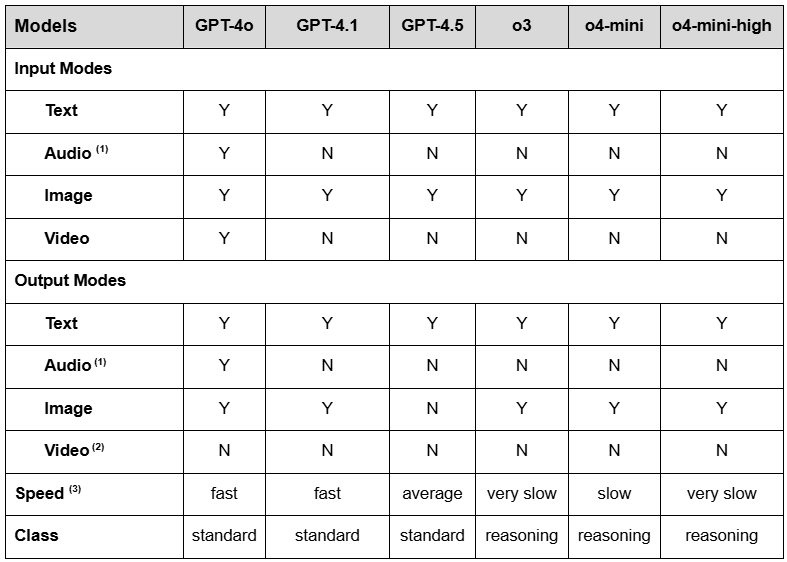
GPT-4o is the only model which supports Audio input or output natively. The other models can support speech-to-text and text-to-speech, but it is outside the model and the model itself is only processing text.
None of the models in ChatGPT natively support the creation of video. However, OpenAI does offer a separate video generation product, Sora.
For speed, a typical measure is “time to first token.” The fast and very fast models have times less than one second, while very slow models are over 30 seconds.
* Table generated by ChatGPT o3 model, with some content and formatting edits by author. Features may have changed since date of publishing (5/26/2025)
Looking at this table, you can see that in most cases the default model, GPT-4o, has the broadest set of capabilities, and indeed is likely the one most suited for your typical sets of tasks. Where the other models, especially o3 and o4-mini, are valuable are for specific types of work, such as complex analysis, computer coding, or specialized scientific or engineering work. While GPT 4.1 looks similar to the others, it is focused on supporting coding and “complex instruction following” where you are looking for it to do very specific things (for example create output in a very structured format). In most cases, the best advice is to start with the default model, and if you aren’t happy with the results, then look to one of the other models that might be more appropriate to your work.
In our next post we’ll look at some other features of these tools that are available and can help solve particular problems or do specific types of work.
Content Note: Except as noted, this article was written entirely by the Author, with light copy editing provided by Google Gemini. Research support provided by ChatGPT.